

- Бесплатный источник данных: правительство
- Бесплатный источник данных: финансово-экономические данные
- Генерация данных с python
- Добавление, удаление, поиск, сортировка записей таблицы
- Как это работает?
- Классификация баз данных
- Отбор записей таблицы
- Связи между таблицами
- Создаем базу данных на примере службы доставки и разбираем запросы sql
- Столбцы
- Таблицы реляционной бд
- Уровни работы с данными
- Ускорение вставки значений
Бесплатный источник данных: правительство
- Data.gov: это первый этап, на котором правительство США бесплатно предоставляет информацию о климате и преступности в Интернете.
- Data.gov.uk: Вот наборы данных от всех центральных департаментов Великобритании, а также от многих других местных и государственных органов. Он служит порталом для всех видов информации обо всем, включая бизнес и экономику, преступность и правосудие, оборону, образование, окружающую среду, правительство, здравоохранение, общество и транспорт .
- Бюро переписей США: Этот сайт содержит последние правительственные статистические данные о жизни американских граждан, включая население, экономику, образование, географию и многое другое.
- CIA World Factbook: данные по всем странам мира; фокусируется на проблемах истории, правительства, населения, экономики, энергетики, географии, связи, транспорта, военных и транснациональных корпораций для 267 стран.
- Socrata: Socrata — компания по разработке программного обеспечения, ориентированная на миссию, которая является еще одним интересным местом для изучения правительственных данных с помощью некоторых встроенных инструментов визуализации. Ваши данные как услуга были приняты более чем 1200 правительственными агентствами для открытых данных, управления производительностью и управления на основе данных.
- Портал открытых данных Европейского Союза: Портал открытых данных Европейского Союза: это единственная точка доступа к растущему диапазону данных от учреждений и других органов Европейского Союза. Увеличение данных включает в себя экономическое развитие в пределах ЕС и прозрачность в рамках институтов ЕС, включая географические, геополитические и финансовые данные, статистику, результаты выборов, правовые акты и данные о преступности, здравоохранении, окружающей среде, транспорте и научное исследование. Они могут быть повторно использованы в разных базах данных и отчетах. И еще, различные цифровые форматы доступны от институтов ЕС и других органов ЕС. Портал предоставляет стандартизированный каталог, список приложений и веб-инструментов, которые повторно используют эти данные,
- Канадские открытые данные — это пилотный проект со множеством правительственных и геопространственных данных. Это поможет вам понять, как правительство Канады создает большую прозрачность, подотчетность, увеличивает участие граждан и стимулирует инновации и экономические возможности посредством открытых данных, открытой информации и открытого диалога.
- Datacatalogs.org: предлагает открытые данные от правительства США, ЕС, Канады, CKAN и многое другое.
- U.S. National Center for Education Statistics(NCES): является основным федеральным органом по сбору и анализу данных, касающихся образования в США / других странах.
- UK Data Service включает в себя основные опросы, спонсируемые правительством Великобритании, транснациональные обследования, продольные исследования, данные переписей Великобритании, международные статистические данные, данные о торговле и качественные данные.
Бесплатный источник данных: финансово-экономические данные
- Открытые данные Всемирного банка: образовательная статистика по всему: от финансов до показателей предоставления услуг.
- Экономические данне МВФ: невероятно полезный источник информации, включая отчеты о глобальной финансовой стабильности, региональные экономические отчеты, международную финансовую статистику, курсы валют, направление бизнеса и многое другое.
- База данных ООН Comtrade: свободный доступ к подробным данным о мировой торговле с визуализациями. UN Comtrade является хранилищем официальной статистики международной торговли и соответствующих аналитических таблиц. Все данные могут быть доступны через API.
- Глобальные финансовые данные: Обладая данными о более чем 60 000 компаний, охватывающих 300 лет, Глобальные финансовые данные представляют собой уникальный универсальный источник для анализа поворотов мировой экономики.
- Google Finance: котировки и графики акций в режиме реального времени, финансовые новости, конвертации валют или отслеживаемые портфели.
- Google Public Data Explorer : предоставляет публичные данные и прогнозы от различных международных организаций и академических учреждений, включая Всемирный банк, ОЭСР, Евростат и Университет Денвера. Они могут отображаться в виде линейных диаграмм, гистограмм, диаграмм сечений или на картах.
- Бюро экономического анализа США: официальная отраслевая и макроэкономическая статистика США, в первую очередь отчеты о валовом внутреннем продукте (ВВП) США и его различных единицах. Они также предоставляют информацию о личных доходах, корпоративных доходах и государственных расходах в своих национальных счетах доходов и продуктов (NIPA).
- Finder Financial Data Finder в OSU: многочисленные ссылки на все, что связано с финансами, независимо от того, насколько они непонятны, включая онлайн-индикаторы мирового развития, открытые данные Всемирного банка, глобальные финансовые данные, статистические базы данных Международного валютного фонда и EMIS Intelligence.
- Нацональное бюро экономических исследований: макроданные, отраслевые данные, данные о производительности, данные о торговле, международные финансы, данные и многое другое.
- Комиссия США по ценным бумагам и биржам: ежеквартальные наборы данных, полученных в результате воздействия корпоративных финансовых отчетов, представленных в Комиссию
- Визуализация экономики: визуализация данных по экономике.
- Financial Times: Financial Times предоставляет широкий спектр информации, новостей и услуг для мирового бизнес-сообщества.
Генерация данных с python
Я работал с Pandas и проектом, который раньше назывался Elizabeth, а сейчас Mimesis:
Его использовал, чтобы генерировать большое количество псевдоперсональных данных для тестирования зарплатных проектов. Вот пример алгоритма генерации сотрудниц.

В цикле формируется 600000 строк, и чтобы Mimesis сгенерировал русские имена и фамилии, мы в строке 16 задаем персону для русского языка. В классе person у нас появляются все псевдослучайные персональные данные. Если мы возьмем, например, поле surname или name и вставим их в наши поля Pandas, то получим женскую фамилию и женское имя. Несложным алгоритмом можно получить отчество.

Для этого нужно сгенерировать уже мужское имя и посмотреть на какую букву алфавита оно заканчивается. Если на простую букву, например, имя Кирилл заканчивается на букву «Л», то чтобы сгенерировать женское отчество от имени Кирилл, нужно добавить «овна» — Кирилловна.
Аналогично генерируются мужские отчества — Иван — «ович».
На Python можно генерировать другие данные, выполнять транслитерацию и генерировать номера.

Ещё Pandas предоставляет удобный интерфейс для того, чтобы удалить дубликаты в одну строку.
df = pd.DataFrame(rowList)
df = pd.drop_duplicates(keep="first")Или для того, чтобы массово обновить все поля всех строк, например, сказать, что в этом датасете все родились 25 ноября:

Я использовал Pandas для того, чтобы не разбираться с форматами Excel, а сохранить готовые данные в CSV или XLS файлы.

Добавление, удаление, поиск, сортировка записей таблицы
Информация БД постоянно обновляется. Способы добавления и удаления записей в ее таблицах зависят от возможностей, предоставляемых СУБД.
Наиболее просто это осуществляется в тех СУБД, которые имеют графический интерфейс. Например, для добавления записи в таблицу MS Access достаточно установить курсор в последнюю строку таблицы и ввести данные в поля. Эта последняя строка всегда пустая и помечена слева символом *. Чтобы быстро попасть в нее, можно воспользоваться кнопкой Новая (пустая) запись в строке состояния таблицы.
Для перехода от одного поля к другому используют клавишу Enter. Переходить от одной записи к другой можно с помощью клавиши Enter, мыши или кнопок переходов в строке состояния. Для удаления записи достаточно выделить ее (щелкнуть мышью слева от нее, в зоне выделения) и нажать клавишу Delete.
Как правило, для ввода данных в таблицы создают специальные объекты базы данных — формы. Они содержат поля одной или нескольких таблиц, а также вспомогательные элементы, обеспечивающие удобство ввода и редактирования данных.
Для поиска данных в таблице существуют разные способы. Например, можно воспользоваться автоматическим поиском по содержимому таблицы и переходить от одного найденного значения к другому. Иной способ — упорядочить (отсортировать) записи таблицы определенным образом, что облегчит поиск нужной информации. Наконец, можно использовать механизм отбора данных — фильтрацию и запросы.
В MS Access для поиска значения достаточно ввести фрагмент искомого значения в поле Поиск строки состояния таблицы. Уже в процессе ввода курсор переместится в соответствующую запись. Для перехода к следующему результату надо нажать клавишу Enter.
Сортировка данных в таблице — это упорядочение ее записей. Для сортировки надо указать поля сортировки и порядок (по возрастанию или по убыванию значений). Записи в таблице сортируются целиком.
Например, при сортировке таблицы абитуриентов по дате поступления записи с ранней датой будут целиком перемещены вверх по отношению к записям с поздней датой.
В MS Access для сортировки служат команды «По возрастанию» и «По убыванию» в заголовке каждого поля таблицы и на вкладке ленты Главная.
Сортировка полей типа «дата» учитывает календарную последовательность.
Порядок сортировки полей символьного типа (строк) определяется таблицей кодировки символов. Строки сравниваются посимвольно слева направо до первого несовпадающего символа. Символ, имеющий меньший код, определит меньшее значение всего поля. Например, значение строки «март» больше значения «май», т. к. код символа «р» больше кода символа «й».
Если строки имеют одинаковую длину и содержат одну и ту же последовательность символов, то они равны.
| Пример 3 Сравнить значения полей «Полевой» и «поле». Решение. При сравнении первых же символов обнаруживаем, что код символа «П» меньше кода «п». Следовательно, вся строка «Полевой» меньше, чем «поле» (несмотря на то что слово «поле» короче, строки полностью не совпадают). Пример 4 Указать порядок записей в таблице после сортировки ее по полю Класс.
Решение. Учитывая, что в поле Класс значения содержат буквы, — это поле символьного типа. Тогда при сравнении его значений сначала будут располагаться те, у которых меньше код первого символа. Первым будет значение «10а» (код его первого символа «1» — наименьший из всех). За ним следует значение «5а», затем «5б» (первые символы «5» у них одинаковы, у вторых код «а» меньше кода «б»). Следующий первый символ — «7» — у значения «7а». И наконец, последними будут значения «9а» и «9б». В соответствии с этим порядком будут перемещены записи таблицы в результирующем наборе: сначала 5–я, затем 6–я, 2–я, 1–я, 3–я, 4–я. Такой результат сортировки символьных значений (10–й класс оказался раньше 5–ого) может оказаться неожиданным для пользователей. Поэтому его учитывают при разработке БД (например, создают два поля для названия класса — отдельно для номера и буквы). Ответ: Порядок записей — 5, 6, 2, 1, 3, 4. |
Как это работает?
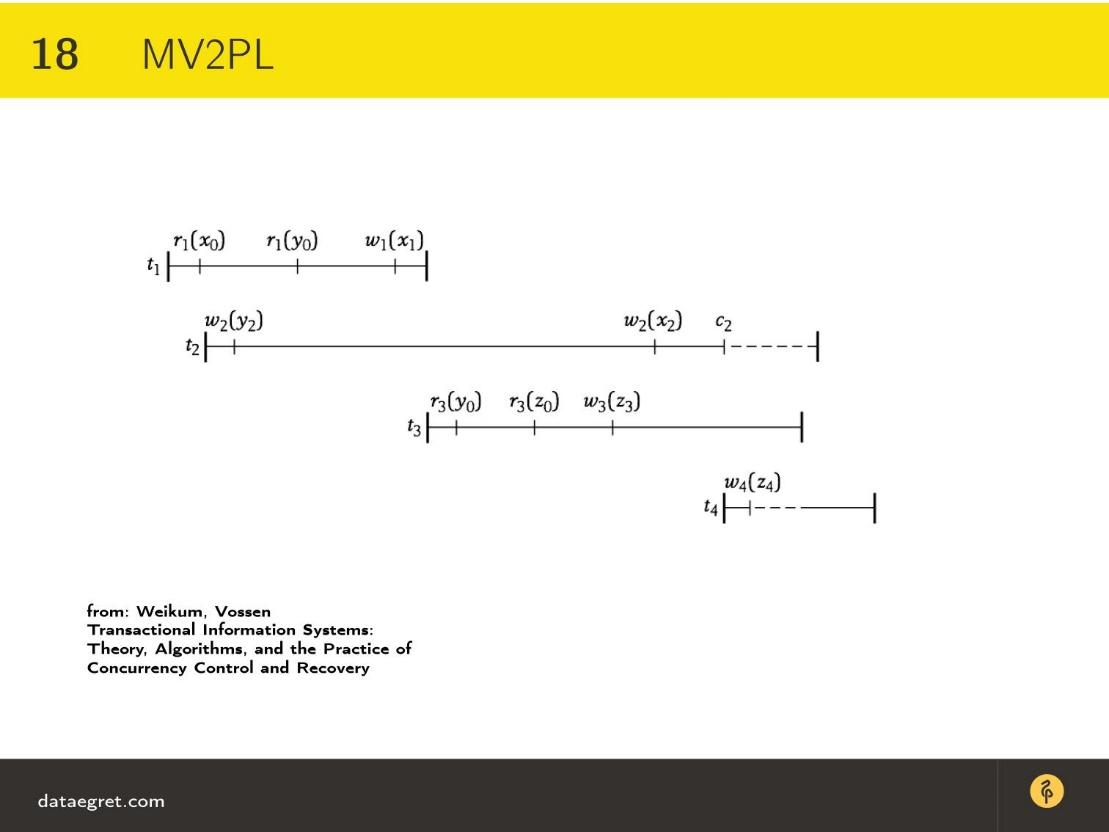
Диаграмма более-менее такая же, как с двухфазным блокированием. Это разновидность версионного шедулинга транзакций, то есть это все равно алгоритм двухфазного блокирования, только мультиверсионный.
Добавляется еще такая фишка, как нижний индекс — 0, 1, 2 — это номер версии.
- Когда мы пошли исполнять транзакцию t1, имеется чтение x0, т.е. самой изначальной версии.
- Дальше в t2 мы начинаем записывать y другой версии, потому что он был изменен.
- В транзакции t1, которая началась раньше, чем мы начали записывать y, до сих пор видно предыдущую версию y0, поскольку t2 еще не завершилась, и мы и спокойно начать с ней работать.
- Поскольку транзакция t1 заканчивается раньше, чем w2(y2), то произойдет перечитываниеy,и после этого в транзакции t 2 выполнится нормальная работа, а другая транзакция просто нормально завершится.
Если попробовать представить, что здесь нет предыдущих версий, то сразу начнутся длинные пунктиры. Когда нужно будет прочитать
y
, не начнется сплошная линия, а будет пунктир, потому что
w2y
) будет ждать, пока она завершится
t1
. Соответственно, расписание разъедется в ширину и все будет сильно медленнее.
В этом большой плюс MVCC. Мультиверсионность на самом деле быстрее, чем блокировка, это не просто маркетинговая фича.
А что, если в момент транзакции, которая явно имеет ненулевую длительность, произойдет сбой, например, развалится жесткий диск под базой данных или выдернут провода из сервера?
На самом деле мы к этому готовы, потому что транзакции выполняются так. Рассмотрим абстрактную базу данных:
Есть некий объем памяти, который обобществлен между разными процессами или тредами, в которых обрабатываются клиентские подключения. У треда есть свой объем памяти, куда приходит SQL-запрос. В этом объеме памяти SQL запрос (или запрос на другом языке) прекомпилируется, интерпретируется, перестраивается каким-то образом.
Дальше он идет за данными, которые ему нужно прочитать и изменить. Эти данные на диске лежат специальным образом. Если заглянуть глубже в хранение, они лежат фиксированными кусками (страничками) в PostgreSQL это 8Кб, в Oracle можно разного размера использовать. В разных базах данных по-разному.
Эта страничка очень удобна тем, что в ней лежит куча разных данных (фактически в ней лежат tuple (кортежи) То есть есть табличка, а в ней строчки, эти строчки упакованы в большие странички.
Если запросу нужны данные с одной из страничек, он просто поднимает эту страничку себе в память и все воркеры, треды и процессы базы данных будут иметь к ней доступ. Если нужно много, то он поднимет несколько. Они будут закэшированы — это удобно, производительно — память быстрее, чем диски, все дела.
Если нужно поменять хотя бы одну запись хотя бы на одной страничке, вся страничка будет помечена, как так называемая «грязная». Это делается потому, что так удобнее. Мы рисовали на схеме ресурсы x и y — здесь это странички.
На самом деле база данных умеет блокировать и на более гранулярном уровне, в том числе единичную запись. Но сейчас мы рассуждаем о более теоретических вещах, а не о тонкостях глубокой реализации.
Соответственно, страничка помечена как «грязная», и у нас возникает проблема, которая заключается в том, что теперь слепок в памяти отличается от того, который на диске. Если мы сейчас упадем, память не персистентна, мы потеряем информацию о «грязных» страничках.
Поэтому нужно сделать следующую операцию: где-то на бумажке записать, какие изменения мы проделали, чтобы, когда поднимемся, прочитать эту бумажку и, используя информацию из нее, восстановить страничку до того состояния, в которое мы ее привели этим апдейтом.
Поэтому прежде, чем ответ от транзакции вернется снова к клиенту, происходит запись в так называемые Write Ahead Log. Это та самая бумажка, которая позволяет записывать быстро — запись в WAL последовательная, нам не надо искать, куда вставить в огромный data-файл это дело.
Мы записали в лог информацию о страничке и дальше вернули управление — все хорошо. Если в какой-то момент упали, то читаем назад Write Ahead Log и используя информацию об этих изменениях, можем чистые странички докатить до уровня «грязных». База данных у нас снова новая.
Это позволяет произвести то самое восстановление, которое нам нужно было обеспечить, исходя из проблем хранения данных, и позволяет восстановиться на самую последнюю транзакцию, на самое последнее действие, которое произошло перед тем, как Марь Иванна вытащила сервер из розетки.
Этот алгоритм называется ARIES и в современном виде сделан достаточно давно. Фундаментальная статья по его устройству и способе восстановления в реляционных базах данных была опубликована Моханом в 1992 году.
С тех пор теории особо не добавилось — Write Ahead Log с тех пор остался Write Ahead Log. Они все используют концепцию страничек и концепцию записей изменений в лог. Лог может по-разному называться и в разных местах располагаться:
В принципе, все везде более-менее одинаково — чтобы восстановиться, мы используем WAL.
Важный момент состоит в том, что все это было бы очень непроизводительно, если бы мы просто от начала времен писали WAL. Он бы рос и рос, а мы потом очень бы долго накатывали эти изменения в базу данных.
Классификация баз данных
В зависимости от характера данных различают фактографические и документальные базы данных.
Фактографические БД содержат информацию, относящуюся к определенной предметной области и представленные в строго определенном формате. Например, фактографическими являются базы данных кадрового состава учреждения, транспортных систем, научных данных, сведений о населении, о природных ресурсах и т. д.
Документальные БД служат для хранения и работы с документами. Часто это документы на естественном языке — монографии, публикации в периодике, тексты законодательных актов и т. д. Зачастую документальные БД содержат видео– и звуковые документы.
Современные БД все чаще сочетают в себе признаки документальных и фактографических баз.
По способу хранения данных различают централизованные и распределенные БД.
В централизованных БД все данные хранятся на одном компьютере (локальном или сетевом). В распределенных БД части базы сохраняются на множестве компьютеров, объединенных между собой в сеть.
В зависимости от вида организации данных различают следующие основные модели представления данных в базе:
- иерархическую;
- сетевую;
- реляционную.
Наиболее распространенной из этих моделей является реляционная. Сегодня появляются новые виды организации БД, как правило, имеющие в своей основе реляционный подход.
В иерархической модели данные представляют в виде древовидной (иерархической) структуры. В ней существует строгая подчиненность элементов, один из которых главный, остальные подчиненные. Такая организация данных удобна для работы с информацией, упорядоченной по уровням, однако для данных со сложными логическими связями она оказывается слишком громоздкой. Графическое представление модели — дерево.
В сетевой модели данные организуются в виде произвольного графа, т. е. связи между элементами произвольны. Она более гибкая, в ней нет явно выраженного главного элемента, существует возможность установления горизонтальных связей. Недостатком ее является высокая сложность реализации.
Кроме того, значительным недостатком иерархической и сетевой моделей является то, что структура данных задается на этапе разработки БД и не может быть изменена позже, при организации доступа к данным.
Реляционная модель представляет собой совокупность таблиц, которые также называют отношениями (отсюда и название: англ. relation — отношение). Эта модель была предложена в 70–х годах XX века сотрудником фирмы IBM Эдгаром Коддом. Она основана на теории множеств и математической логике.
Доказано, что любую структуру данных можно свести к табличной форме.
Достоинствами реляционной модели данных являются простота, гибкость структуры, удобство компьютерной реализации, наличие теоретического описания. Большинство современных БД для персональных компьютеров являются реляционными.
В реляционной БД эффективно реализуются следующие операции:
- сортировка данных (например, учащихся по алфавиту, сеансов по времени);
- выборка данных по группам (например, все маршруты по направлениям, все учащиеся по классам);
- поиск записей (например, поиск книг по их автору, товаров по наименованию) и т. д.
Отбор записей таблицы
Зачастую требуется отобрать часть записей таблицы, которые удовлетворяют некоторому условию. Это условие называют критерием отбора.
Отбор записей в самой таблице путем задания условия отбора называется фильтрацией таблицы. Фильтрация позволяет отобрать записи из одной таблицы для простых условий. Если требуется выбрать данные сразу из нескольких таблиц или условие является сложным, создают специальные объекты базы данных — запросы. Они представляют собой средства получения данных из БД в соответствии с требованиями пользователя.
И в том и в другом случае условие отбора должно быть записано в виде логического выражения. Логическое выражение — выражение, содержащее логические и арифметические операции, а также операции сравнения. Результатом логического выражения является логическая величина («истина» либо «ложь»). К логическим выражениям применяются все правила вычисления результатов логических операций.
Простейшая форма логического выражения в условии отбора — указание имени какого–либо поля логического типа. Поскольку такие поля имеют значения «истина» или «ложь», то результат выражения совпадет со значением поля.
Простые логические выражения могут содержать операции сравнения (их еще называют отношениями): больше (>), меньше (<), больше или равно (>=), меньше или равно (<=), равно (=), не равно (≠ или <>). Сравнение данных производится по тем же правилам, что и при сортировке.
Операции сравнения накладывают требования на значения поля. Например, выражение Количество <= 100 требует найти все записи таблицы, в которых значение поля Количество не превышает 100.
Результатом отбора являются те записи таблицы, для полей которых логическое выражение принимает значение «истина».
| Пример 5 Для приведенной таблицы определить результат отбора в соответствии с заданными логическими выражениями. Поля Отправление и Назначение — символьные, Доставка — логическое, остальные — числовые.
Решение. A) В результате будут отобраны записи, содержащие в поле Отправление значение «Женева». Это строки с номерами поездок 12, 460, 108. Б) В этом логическом выражении участвует только название логического поля Доставка. Результатом отбора будут все записи, у которых это поле содержит значение «истина» («да»), т. е. записи о поездках с номерами 12, 3, 23. B) Требуется найти значения в поле Назначение, которые больше значения «С». Это должны быть строки, которые начинаются с символа «С», но длиннее; или строки, которые начинаются с символа, код которого больше кода «С» (т. е. следующие по алфавиту). Из всех строк в поле Назначение подходит только значение «Стамбул» — все остальные начинаются с символов, предшествующих «С» в алфавите. Результатом будет запись о поездке с номером 460. Ответ: результаты отбора — записи о поездках с номерами: А) 12, 460, 108; Б) 12, 3, 23; В) 460. |

Составные логические выражения конструируются из простых при помощи логических операций И, ИЛИ, НЕ. Эти операции удовлетворяют правилам алгебры логики. Порядок выполнения операций определен в алгебре логики (сначала НЕ, затем И, затем ИЛИ). Для изменения этого порядка используются скобки.
Результат применения операции И (логическое умножение) равен «истина» только тогда, когда обе части выражения истинны.
Результат применения операции ИЛИ (логическое сложение) равен «истина» только тогда, когда хотя бы одна из частей выражения истинна.
Результат применения операции НЕ (логическое отрицание) к какому–либо логическому выражению — «истина» тогда, когда исходное выражение ложно, и «ложь» — когда оно истинно.
| Пример 6 Для таблицы, приведенной в примере 5, определить результат отбора в соответствии с заданными логическими выражениями.
Решение. A) Сначала отбираются строки, удовлетворяющие первой части выражения (записи о поездках из Женевы — с номерами 12, 460, 108). Затем из них отбираются строки, которые удовлетворяют второй части выражения (записи о поездках с расстоянием свыше 1000 — с номерами 12 и 460). Б) Сначала отбираются записи таблицы, удовлетворяющие первой части условия (о поездках с номерами 12, 460, 108). Затем из них отбираются те, в которых поле Доставка имеет значение «истина». Из отобранных строк только запись о поездке с номером 12 имеет значение поля Доставка «да» («истина»). B) В соответствии со скобками сначала отбираются записи, удовлетворяющие первой части логического выражения. Затем — второй его части, после чего из них отбираются записи, удовлетворяющие обоим частям выражения (попавшие и в один, и в другой результаты отбора). Первой части условия удовлетворяют записи с номерами поездок 12, 16, 460, 108. Второй части условия — записи с номерами поездок 12, 168, 3, 23, 16. Записи, попавшие в оба результата отбора, имеют номера 12, 16. Ответ: результаты отбора — записи о поездках с номерами: А) 12, 460; Б) 12; В) 12, 16. |
| Пример 7 Для таблицы, приведенной в примере 5, записать условие отбора записей о поездках: Решение. А) Условие о пункте назначения представляет логическое выражение Назначение =»Стамбул». Условие об ограничении расстояния: Расстояние <= 1000. По условию оба эти ограничения должны выполняться одновременно, поэтому для объединения следует использовать операцию логического умножения: Если применить это условие отбора к исходным данным, то в результате не будет получено ни одной строки, так как в таблице нет ни одной записи, удовлетворяющей условию. Тем не менее, это не означает, что условие записано неверно, а лишь то, что в данный момент времени таких поездок не имеется. Б) для отбора поездок из Женевы или Брюсселя должно быть записано условие Отправление = «Женева» ИЛИ Отправление = «Брюссель». Для ограничения расстояния: Расстояние >= 1000 И Расстояние <= 2000. Затем оба этих условия надо объединить логической операцией И, так как они должны быть выполнены одновременно: Вторую часть выражения можно заключить или не заключать в скобки, поскольку обе операции И имеют одинаковый приоритет выполнения. |
Связи между таблицами
Как правило, реляционная БД состоит из набора взаимосвязанных таблиц, некоторые из них являются главными, остальные — подчиненными. Организация связи (отношений) между таблицами называется связыванием или соединением таблиц.
Связи между таблицами устанавливаются при создании БД. Поля, которые используются для связывания таблиц, называются полями связи. Поле связи подчиненной таблицы называется внешним ключом.
Существуют следующие виды связей между таблицами:
- отношение «один–к–одному»;
- отношения «один–ко–многим» и «много–к–одному»;
- отношение «много–ко–многим».
Отношение «один–к–одному» означает, что одной записи в главной таблице соответствует не более одной записи в подчиненной таблице. Полями связи в таком случае являются ключевые поля обеих таблиц.
Отношение «один–к–одному» обычно используют, чтобы разбить таблицу с большим числом полей на несколько таблиц. В этом случае в первой таблице остаются поля с наиболее важной и часто используемой информацией, а остальные поля переносятся в другую таблицу.
Отношение «один–ко–многим» означает, что одной записи главной таблицы может соответствовать несколько записей подчиненной таблицы, а каждой записи подчиненной — только одна запись главной таблицы. Это наиболее часто встречающийся вид отношений.
Например, в главной таблице хранятся данные о книгах, а в подчиненной — данные о выдаче книг читателям. Одну книгу могут брать в библиотеке для чтения многократно, поэтому одной записи в главной таблице может соответствовать несколько записей в подчиненной таблице.
Отношение «много–к–одному» отличается от отношения «один–ко–многим» только направлением. Если на отношение «один–ко–многим» посмотреть со стороны подчиненной таблицы, а не главной, то оно превращается в отношение «много–к–одному».
Отношение «много–ко–многим» означает, что каждой записи одной таблицы может соответствовать несколько записей другой таблицы, и в то же время каждой записи второй таблицы — несколько записей первой.
Подобное отношение реализуется, например, в базе данных библиотеки между таблицами книг и читателей. Любую книгу могут взять для чтения (по очереди) много читателей, и любой читатель может взять несколько книг.
Для отношения «много–ко–многим» сложно организовывать связи между таблицами и взаимодействие между их записями. Многие СУБД, в том числе MS Access, не поддерживают организацию подобного отношения. В таких случаях его реализуют через отношение «один–ко–многим».
Создаем базу данных на примере службы доставки и разбираем запросы sql
Сегодня мы рассмотрим пример базы данных и различные команды агрегации, группировки, сортировки, соединения таблиц и другое на примере MySQL. Сами данные представляют собой набор таблиц с произвольными названиями и значениями. Структура таблиц и их связи представлены ниже.
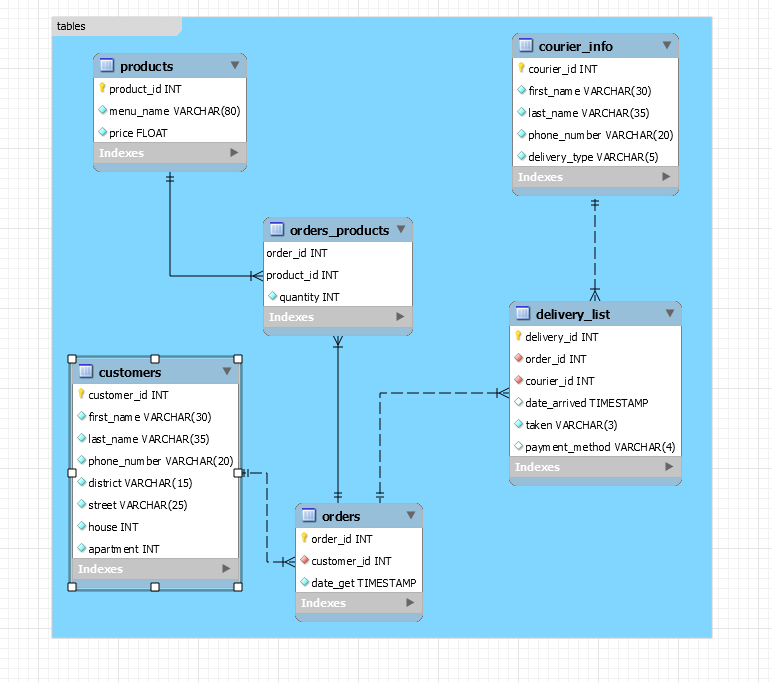
Для понимания дальнейшего Вам будут желательно начальные знания SQL и баз данных. Данное пособие поможет структурировать информацию, обновить память и может выступать в роли шпаргалки, которую вы можете использовать при надобности. Запросы на создание всех таблиц находятся тут.
С содержанием таблиц удобно ознакомиться в формате excel:






Как ни странно, но начнем мы анализ с таблицы, которая не упоминалась выше и не имеет связей с другими. Она представляет собой статистику за год по некоторым ключевым показателям.
Примечание: дабы не загружать статью всеми видами таблиц из запросов, визуально представлены будут только некоторые, а с остальными Вы без проблем можете поэкспериментировать сами.

Агрегация, группировка, сортировка
Сумма заказов за весь год:
SELECT SUM(amount_of_orders) AS orders_per_year FROM year_statistics;
Убывающая сортировка заказов по месяцам:
SELECT month_name, amount_of_orders
FROM year_statistics
ORDER BY amount_of_orders DESC;
Вывести месяц, где больше всего заказов:
SELECT month_name, amount_of_orders FROM year_statistics WHERE amount_of_orders = (SELECT MAX(amount_of_orders)
FROM year_statistics);
Популярность районов по количествам клиентов:
SELECT district
FROM customers
GROUP BY district
ORDER BY COUNT(district) DESC;
Сколько каждый курьер доставил заказов:
SELECT courier_id, COUNT(order_id)
From delivery_list
WHERE date_arrived IS NOT NULL
GROUP BY courier_id;
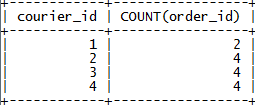
Общие запросы и использование операторов IN, EXISTS, UNION и др.
Выборка клиентов, которые живут в районе «South»:
SELECT * FROM Customers
WHERE district IN ('South');
Информация о заказах, которые не были доставлены клиентам:
SELECT * FROM delivery_list
WHERE taken NOT IN ('Yes');
Запрос продуктов из меню, которые были заказаны:
SELECT menu_name FROM products
WHERE EXISTS
(SELECT * FROM orders_products
WHERE orders_products.product_id = products.product_id);
Запрос тех продуктов, которые не заказывали:
SELECT menu_name FROM products WHERE NOT EXISTS
(SELECT * FROM orders_products
WHERE orders_products.product_id = products.product_id);
Получаем общую таблицу с информацией о клиентах и курьеров:
SELECT 'Customer' AS category, first_name, last_name, phone_number
FROM customers
UNION
SELECT 'Employee' AS category, first_name, last_name, phone_number
FROM courier_info;
INNER, NATURAL, CROSS, LEFT JOIN
Наиболее интересный запрос, который позволяет видеть детали заказа(номер, название блюда, количество и цена). К тому же здесь использован метод ROUND, позволяющий округлять дробные числа:
SELECT orders_products.order_id, products.menu_name, quantity,
ROUND(price*quantity, 2) AS total_price
FROM orders_products
INNER JOIN products ON orders_products.product_id = products.product_id
ORDER BY order_id, quantity;

Еще один довольно любопытный запрос, показывающий детальную информацию по заказам, а также время их доставки:
SELECT *, SEC_TO_TIME(TIMESTAMPDIFF(second, date_get, date_arrived))
AS time_of_delivery
FROM orders
NATURAL JOIN delivery_list;
Не совсем тривиальный запрос на выборку о том, что каждому курьеру на машине доступен любой район из таблицы клиентов:
SELECT DISTINCT courier_info.courier_id, customers.district
FROM courier_info
CROSS JOIN customers WHERE courier_info.delivery_type = 'car'
ORDER BY courier_id;

И напоследок запрос на информацию об имени клиента, его мобильном телефоне и номере заказа:
SELECT customers.first_name, customers.last_name,
customers.phone_number, orders.order_id
FROM customers
LEFT JOIN orders ON customers.customer_id = orders.customer_id;

Заключение
По итогу мы с вами разобрали множество полезных запросов на выборку SQL. Были показаны основные и более редкие операции. В сущности не важно, сколько данных в Вашей таблице — десять или тысяча, от этого запросы не поменяются, а всегда будут оставаться такими же. Главное, чтобы был понятен смысл, количество данных играет намного меньшую роль. Бояться и расстраиваться от того, что у Вас пока не получается получить желаемый запрос, совершенно глупо. Абсолютно нормально, если Вы гуглите, читаете книгу на интересующую тему, а результата так и нет. На это может уходить от десятка минут до целых дней. Мы все люди и одному человеку не под силу знать все. Наберитесь терпения, спросите у товарищей, на форумах и просто продолжайте искать сами, у Вас все получится! Удачи.
Столбцы
Следующий скрипт описывает таблицы и столбцы из всей базы данных. Результат этого запроса, можно скопировать в Excel, где можно настроить фильтры и сортировку и хорошо разобраться с типами данных, использующимися в БД. Так же, обратите внимание на столбцы с одинаковыми именами, но разными типами данных.
SELECT @@Servername AS Server ,
DB_NAME() AS DBName ,
isc.Table_Name AS TableName ,
isc.Table_Schema AS SchemaName ,
Ordinal_Position AS Ord ,
Column_Name ,
Data_Type ,
Numeric_Precision AS Prec ,
Numeric_Scale AS Scale ,
Character_Maximum_Length AS LEN , -- -1 means MAX like Varchar(MAX)
Is_Nullable ,
Column_Default ,
Table_Type
FROM INFORMATION_SCHEMA.COLUMNS isc
INNER JOIN information_schema.tables ist
ON isc.table_name = ist.table_name
-- WHERE Table_Type = 'BASE TABLE' -- 'Base Table' or 'View'
ORDER BY DBName ,
TableName ,
SchemaName ,
Ordinal_position;
-- Имена столбцов и количество повторов
-- Используется для поиска одноимённых столбцов с разными типами данных/длиной
SELECT @@Servername AS Server ,
DB_NAME() AS DBName ,
Column_Name ,
Data_Type ,
Numeric_Precision AS Prec ,
Numeric_Scale AS Scale ,
Character_Maximum_Length ,
COUNT(*) AS Count
FROM information_schema.columns isc
INNER JOIN information_schema.tables ist
ON isc.table_name = ist.table_name
WHERE Table_type = 'BASE TABLE'
GROUP BY Column_Name ,
Data_Type ,
Numeric_Precision ,
Numeric_Scale ,
Character_Maximum_Length;
-- Информация по используемым типам данных
SELECT @@Servername AS ServerName ,
DB_NAME() AS DBName ,
Data_Type ,
Numeric_Precision AS Prec ,
Numeric_Scale AS Scale ,
Character_Maximum_Length AS [Length] ,
COUNT(*) AS COUNT
FROM information_schema.columns isc
INNER JOIN information_schema.tables ist
ON isc.table_name = ist.table_name
WHERE Table_type = 'BASE TABLE'
GROUP BY Data_Type ,
Numeric_Precision ,
Numeric_Scale ,
Character_Maximum_Length
ORDER BY Data_Type ,
Numeric_Precision ,
Numeric_Scale ,
Character_Maximum_Length
-- Large object data types or Binary Large Objects(BLOBs)
-- Помните, что индексы по этим таблицам не могут быть перестроены в режиме "online"
SELECT @@Servername AS ServerName ,
DB_NAME() AS DBName ,
isc.Table_Name ,
Ordinal_Position AS Ord ,
Column_Name ,
Data_Type AS BLOB_Data_Type ,
Numeric_Precision AS Prec ,
Numeric_Scale AS Scale ,
Character_Maximum_Length AS [Length]
FROM information_schema.columns isc
INNER JOIN information_schema.tables ist
ON isc.table_name = ist.table_name
WHERE Table_type = 'BASE TABLE'
AND ( Data_Type IN ( 'text', 'ntext', 'image', 'XML' )
OR ( Data_Type IN ( 'varchar', 'nvarchar', 'varbinary' )
AND Character_Maximum_Length = -1
)
) -- varchar(max), nvarchar(max), varbinary(max)
ORDER BY isc.Table_Name ,
Ordinal_position;
Таблицы реляционной бд
Каждая таблица состоит из строк и столбцов и предназначена для хранения данных об однотипных объектах. Каждая строка содержит информацию об одном конкретном объекте БД (например, книге, сотруднике, товаре), а каждый столбец — конкретную характеристику этого объекта (например, фамилию, название, цену).
В разных записях значения отдельных полей могут повторяться. Но в таблице должно иметься такое поле или набор полей, значение в котором не повторяется ни для одной записи — оно является уникальным для каждой записи. Такое поле называют ключевым полем (ключом) таблицы. По значению ключевого поля можно однозначно получить всю запись таблицы с этим ключевым значением.
Простой ключ состоит из одного поля, а составной — из нескольких полей. В таблице может быть определен только один ключ, который называют первичным ключом. Например, таким полем может служить код изделия, номер автомобиля или читательского билета.
Любая таблица в реляционной БД обладает следующими свойствами:
- каждый элемент таблицы — один элемент данных;
- все поля (столбцы) в таблице являются однородными, т. е. данные в одном столбце имеют один тип (число, текст, дата и т. д.);
- каждое поле имеет уникальное имя;
- одинаковые записи (строки) в таблице отсутствуют;
- порядок следования записей в таблице может быть произвольным.
Каждое поле таблицы имеет определенный тип. Тип — это множество значений, которые может принимать поле, и множество операций, которые можно выполнять над этими значениями. Существуют четыре основных типа для полей БД: символьный, числовой, логический и дата.
Поля символьного типа предназначены для последовательностей символов (тексты, коды и т. д.). Поля даты содержат даты вида «день/месяц/год». числовые поля могут сохранять только числа. Логические поля сохраняют данные, которые могут принимать только одно из двух значений: «да» или «нет» («истина» или «ложь»).
| Пример 1 В таблице сведений об автомобилях требуется сохранять сведения о моделях автомобилей, их мощности, цвете кузова и времени выпуска. Каждый автомобиль характеризуется своим кодом. Определить структуру таблицы. Решение. Перечисленные данные будут составлять поля таблицы. Таким образом, в таблице могут быть определены поля (столбцы) Код автомобиля, Модель, Мощность двигателя, Цвет, Год выпуска. Поле Код автомобиля — ключевое: оно однозначно определяет любую запись таблицы. Типы всех полей, кроме Год выпуска, — символьные; Год выпуска — числовое. Поле Код автомобиля содержит текстовые символы, поэтому имеет символьный тип. Поле Год выпуска содержит не дату, а число, поэтому имеет тип числовой. Записи таблицы содержат данные о конкретных автомобилях.
|

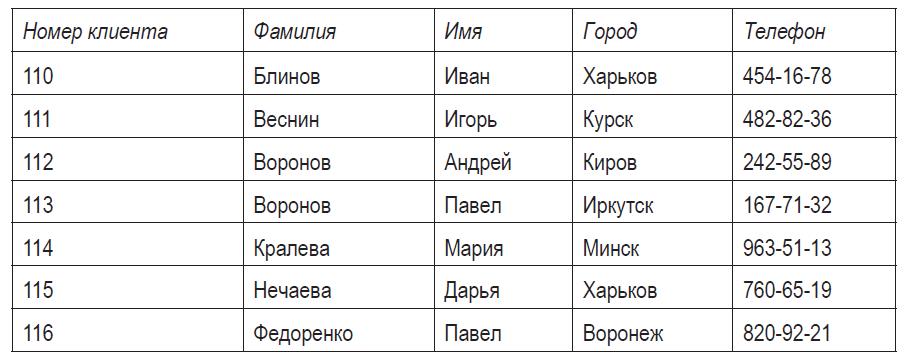
| Пример 2 Определить поля и записи в представленной таблице клиентов. Указать, какое поле может быть в этой таблице ключевым.
Решение. Каждый столбец таблицы содержит некоторую характеристику объекта (клиента). Эти столбцы являются полями таблицы: Номер клиента, Фамилия, Имя, Город, Телефон. Среди всех полей только Номер клиента однозначно определяет конкретного клиента. Поля Фамилия или Имя для этой цели не подходят, т. к. они содержат повторяющиеся фамилии и имена. Даже если бы предложенная таблица не содержала однофамильцев, то такой вариант мог возникнуть позже, при дополнении базы данных. Поэтому поле Фамилия не может однозначно характеризовать клиента. При условии что каждому клиенту присвоен свой, уникальный номер, поле Номер клиента может быть ключевым полем данной таблицы. Каждая строка таблицы содержит сведения об одном объекте (клиенте), поэтому строки таблицы — записи. |
Уровни работы с данными
Итак, есть различные уровни работы с данными:
- Слой доступа к данным, который удобно использовать из языков программирования;
- Слой хранения. Это отдельный слой, потому что обычно хранить данные удобно другими способами, чем использовать: эффективно по памяти, выравнивать, складывать на диск. Это к вопросу о schemaless: схема, которая удобна для хранения, не удобна для доступа.
- «Железо» — слой, где лежат данные, причем там они организованы еще третьим способом, потому что дисками управляет операционная система, и общаются они только через драйвер. В этот уровень мы не будем сильно вникать.
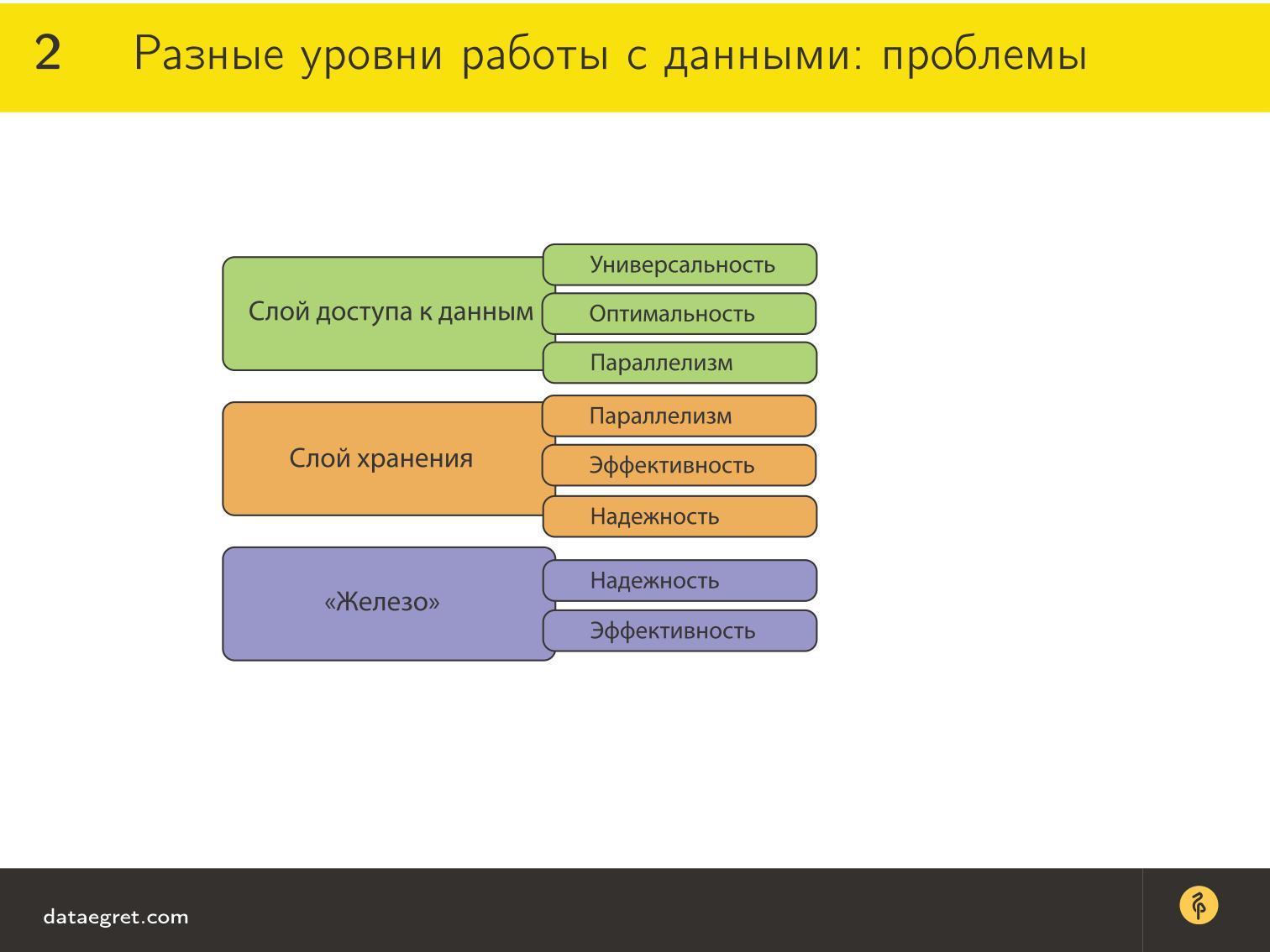
Для слоя доступа к данным есть требования, в выполнении которых мы заинтересованы, чтобы было удобно работать:
- Универсальность, чтобы возможно было с помощью любой технологии запрашивать данные.
- Оптимальность этого запроса. Метод доступа должен быть такой, чтобы хорошо и удобно доставать данные из базы.
- Параллелизм, потому что сейчас все масштабируются, разные серверы одновременно обращаются к базу за одними и теми же данными. Надо сделать так, чтобы максимально использовать преимущества параллелизма и быстрее обрабатывать данные таким способом.
Для слоя хранения
по-прежнему важно сохранение
изначального параллелизма
, чтобы все данные были не побиты, не перезаписаны, не перетерты и т.д.
В то же время они должны быть надежно сохранены и надежно воспроизведены. То есть, если мы что-то записали в базу данных, мы должны быть уверены, что мы это получим обратно.
Если вы работали со старыми базами данных, например, FoxPro, то знаете, что там часто появляются битые данные. В новых базах данных, типа MongoDB, Cassandra и прочих, такие проблемы тоже случаются. Может быть, просто их не всегда замечают, потому что данных уж очень много и заметить сложнее.
Для «железа» на самом деле важна надежность. Это как бы допущение, поскольку мы все-таки будем говорить о теоретических вещах. В нашей модели, если что-то попало на диск, то мы считаем, что там все хорошо. Как заменить вовремя диск в RAID — это сегодня для нас забота админов.
Чтобы решать эти проблемы, есть некоторые подходы, которые очень похожи у разных хранилищ данных — и новых, и классических.
Прежде всего для того, чтобы обеспечить универсальный и оптимальный доступ к данным, есть язык запросов. В большинстве случаев это SQL (почему именно он, мы подискутируем дальше), но сейчас просто хочу обратить внимание на тенденцию.
Многие Key-value-storage в основном делались для того, чтобы из любимого языка программирования было проще ходить за данными, а SQL не очень хорошо вяжется с любимым языком программирования. Он высокоуровневый, декларативный, а нам хочется объектов, поэтому появилась идея, что SQL не нужен.
Но большинство этих технологий сейчас на самом деле придумывают какой-то свой язык запросов. В Hibernate очень развит свой собственный язык запросов, кто-то использует Lua. Даже те, кто раньше использовал Lua, делают свои реализации SQL. То есть сейчас тенденция такая: SQL опять возвращается, потому что удобный человеко-читаемый язык работы со множествами все равно нужен.
Плюс к тому по-прежнему удобно табличное представление. В той или иной степени во многих базах данных по-прежнему имеются таблички, и это далеко не случайно — таким образом легче оптимизировать запросы. Вся математика оптимизации завязана вокруг реляционной алгебры, и когда есть SQL и таблички, работать гораздо проще.
В слое хранения возникает такое понятие, как сериализация. Когда есть параллелизм и конкурентный доступ, нам нужно обеспечить, чтобы на процессор, на диск это приезжало в более-менее предсказуемом порядке. Для этого нужны алгоритмы сериализации, которые реализуются в слое хранения.
Опять же, если что-то пошло не так и база данных упала, нам нужно ее быстро поднять.
Как вы считаете, можно ли написать 100% надежное отказоустойчивое хранилище? Наверное, вы знаете, что база данных надежно работает только тогда, когда есть механизм, чтобы ее быстро поднять, если она упала.
Для этого нужно восстановление, потому что, что ни делай, где-нибудь будет слабое звено и очень большие накладные расходы на синхронизацию. Мы можем сделать сотню копий на сотню серверов, а в результате сгорит питание или какой-то коммутатор, и будет плохо и больно.
Для «железа» на самом деле важно, чтобы база данных была хорошо интегрирована с ОС, работала производительно, вызывала правильные syscalls и поддерживала все фишки ядра по быстрой работе с данными.
Ускорение вставки значений
Чтобы ускорить вставку значений не только за счет использования хранимых процедур, а еще за счет оптимального процесса, я рекомендую до генерирования данных сделать еще 4 предварительных шага:
1) Сохранить схему БД в виде файла — вдруг что-то поломается;
2) Отключить индексы запросом для Postgres:
UPDATE pg_index
SET indisready=false
WHERE indexrelid = (
SELECT oid
FROM pg_class
WHERE
relname in (
'таблица1'
,'таблица2'
)
);Здесь мы говорим, что нужные индексы у нас теперь (indisready=false) отключены.
3) Отключить триггеры, если они есть:
ALTER TABLE public.таблица1
DISABLE TRIGGER ALL;
ALTER TABLE public.таблица2
DISABLE TRIGGER ALL;4) Удалить ключи:
ALTER TABLE public.таблица1
DROP CONSTRAINT таблица1_pkey;
ALTER TABLE public.таблица2
DROP CONSTRAINT таблица2_pkey;Ключи являются индексами, но отключить их нельзя. Поэтому если вы хотите ускорить тестирование и отказаться от ключей, их можно только удалить. Для этого мы и сохраняли схему БД на первом шаге, чтобы потом проверить, что у нас все хорошо.
5) Сгенерировать данные «хранимками»:
SELECT load_fill_database_test1(1, 1000000);
SELECT load_fill_database_test2(1000001, 2000000);Далее нужно выполнить шаги обратные шагам 4, 3, 2.
5) Создать ключи (ADD CONSTRAINT):
ALTER TABLE public.таблица1
ADD CONSTRAINT PRIMARY KEY(id);
ALTER TABLE public.таблица2
ADD CONSTRAINT PRIMARY KEY(id);6) Включить триггеры, если мы их отключали:
ALTER TABLE public.таблица1
ENABLE TRIGGER ALL;
ALTER TABLE public.таблица2
ENABLE TRIGGER ALL;7) Включить индексы:
UPDATE pg_index
SET indisready=true
WHERE indexrelid=(
SELECT oid
FROM pg_class
WHERE
relname in
('таблица1',
'таблица2')
);Если отключить индексы, а потом вставить данные и включить индексы, индексы автоматически не обновятся. Нужно выполнить переиндексацию.
8) Переиндексировать:
REINDEX public.таблица1;
REINDEX public.таблица2;Теперь Postgres будет знать о всех новых записях, индексы перестроятся и можно сравнить сохраненную схему, которая была на шаге 1, и схему, которая получилась после того, как мы выполнили все шаги.
9) Сравнить схему до и после.
Но данные можно генерировать не только с Postgres. Иногда нужно генерировать сложные данные, например, списки сотрудников, которые получают зарплату, в виде документа Excel. Тогда мне на помощь приходит Python и проект под названием Pandas.